Model Inversion Attacks against Secure Federated Learning Systems
Research Problem
Federated learning (FL) is a distributed learning paradigm that enables its participants to collaboratively train machine learning models without sharing local datasets. In this context, it is considered a privacy-preserving paradigm.
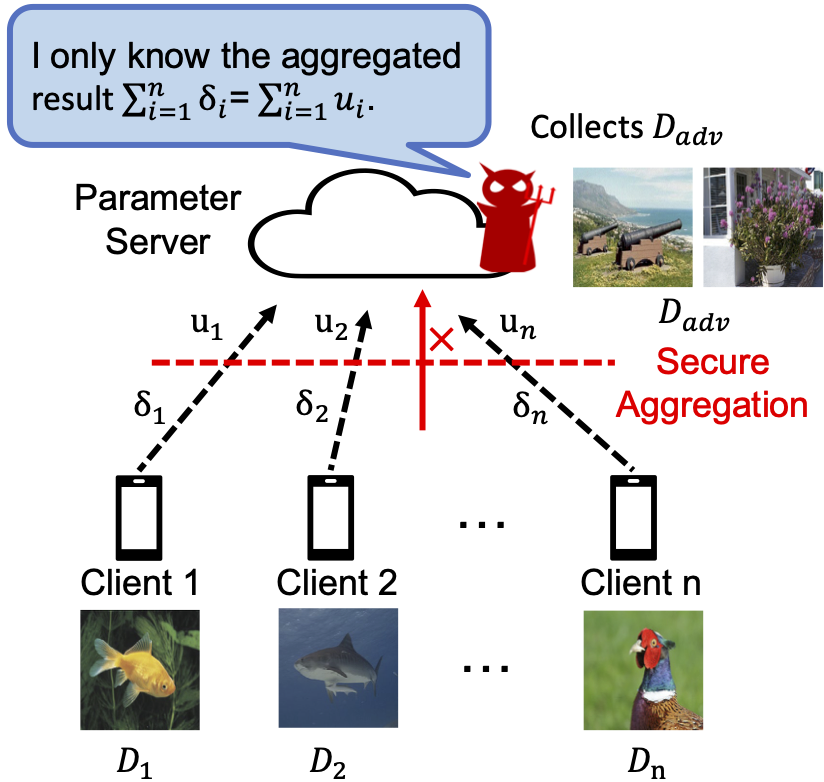
However, recent optimization-based model inversion attacks show that a curious server can reverse the shared model updates between FL participants back to local training samples, challenging this privacy guarantee.
To address this, a multi-party computation mechanism named secure aggregation is proposed, which hides individual model updates behind cryptographic masks but keeps the aggregated results identical to pre-masked values to keep system utility. This prevents the optimization-based attackers from obtaining individual model updates, effectively defending against these attacks.
In this research, we investigate whether the parameter server can still reconstruct local client samples from model updates when the secure aggregation protocol is in place.
Threat model for the model inversion attacks.
Research Work 1: A More Scalable and Efficient Model Inversion Attack
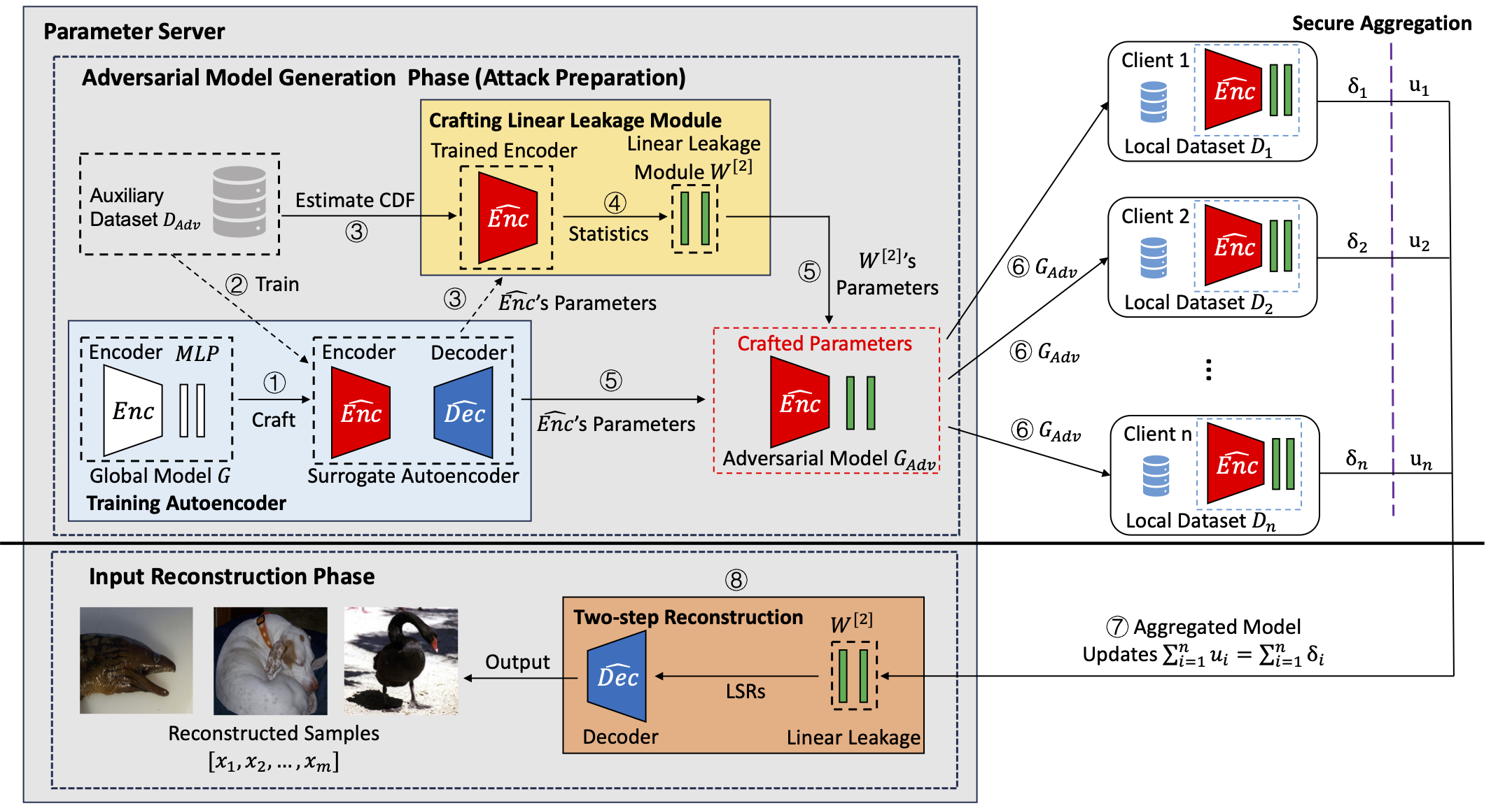
We propose a more powerful model inversion attack named Scale-MIA that not only breaks the secure aggregation but also significantly improves the attack efficiency and scalability.
Our attack identifies the latent space as the key layer to breach the privacy and decompose the complex reconstruction problem into two steps including first reversing the aggregated model updates back to latent space representations (LSRs) via an attack module named linear leakage, and then reversing the LSRs back to local training samples via a fine-tuned decoder.
Our attack only involves closed-form calculations, and thus is much more efficient than existing works.
Scale-MIA is a two-phase attack. The first phase is performed locally to produce essential information to conduct the second phase. The second is the actual attack phase, during which the attacker interacts with the clients and reconstructs their local training samples.
Results
We implement our attack on popular machine learning models and datasets and the results show that our attack can reconstruct hundreds of local training samples simultaneously within a few seconds.
The comparison between the original images and the reconstructed images with batch size 64 on CelebA.
Research Work 2: Reconstructing Multi-modal Data in Medical Federated Learning
In this research, we propose MedLeak, a novel and powerful MIA that is capable of recovering high-quality medical samples efficiently, even when state-of-the-art cryptography-based defense mechanisms such as secure aggregation are employed.
MedLeak can target both medical image and text data, demonstrating its broad applicability in the medical domain.
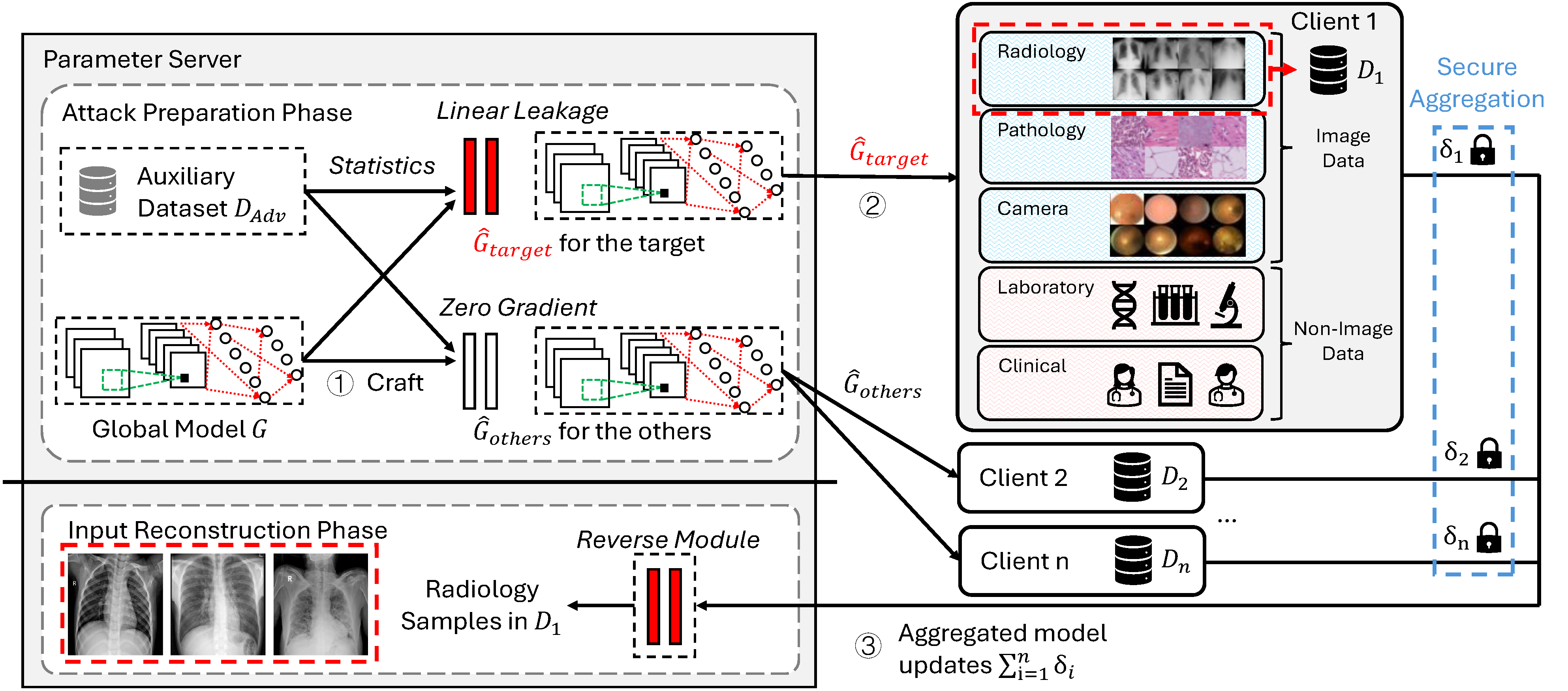
MedLeak designs two modules including the “Zero Gradient” module for all clients except the victim and the “Linear Leakage” module for the target victim. The first module can retrieve individual model updates from the aggregated results, and the second module can efficiently reverse the individual model updates back to local samples.
MedLeak can find the ownership of the recovered images.
MedLeak attack flow. MedLeak is a two-phase attack. In the first preparation phase, the attacker generates the adversarial global model. In the second reconstruction phase, the attacker sends the adversarial models to the clients and recovers the local samples when it receives their feedback. MedLeak can reconstruct both image and non-image data and this figure demonstrates the reconstruction of the medical radiology images.
Results
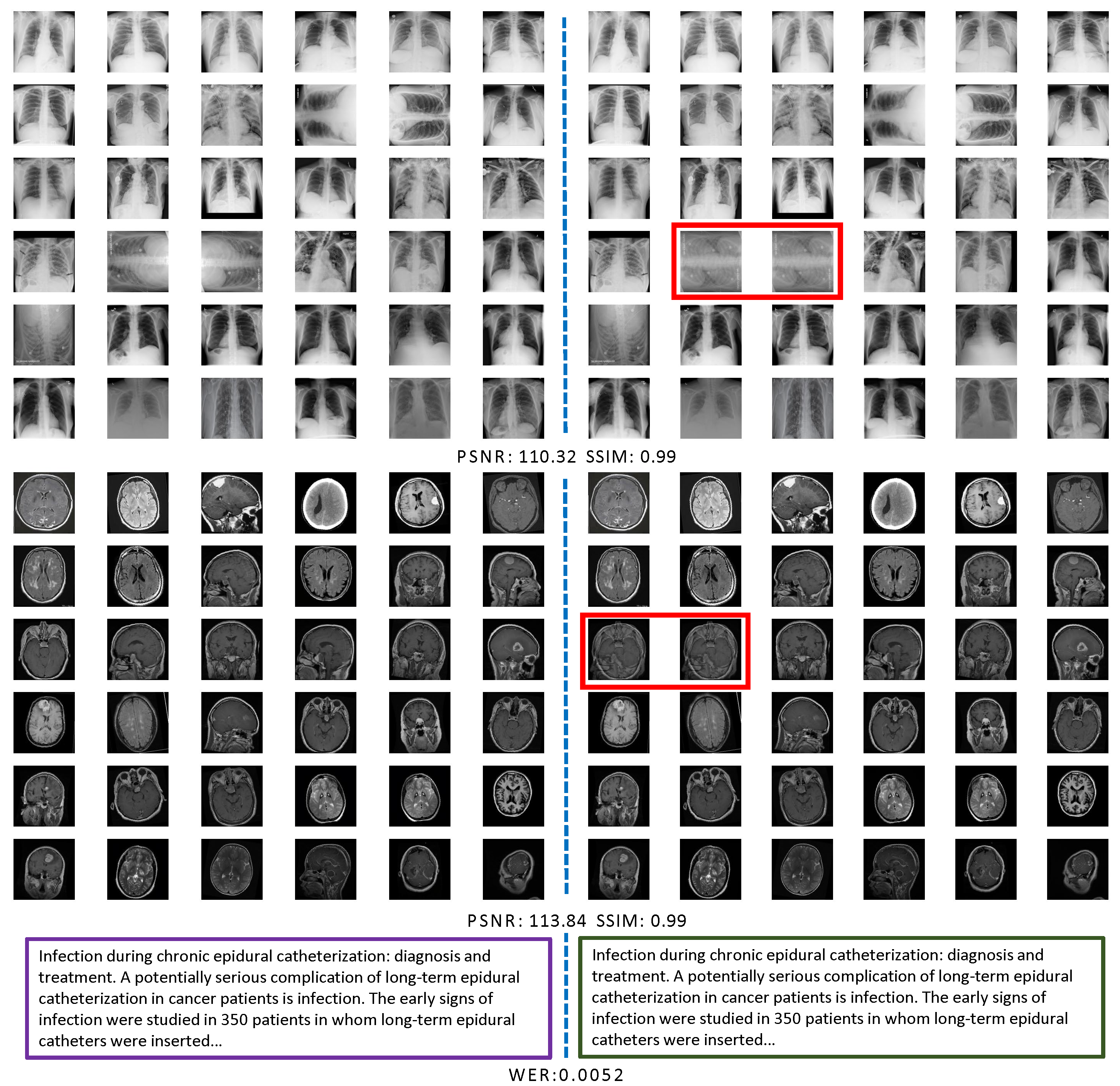
We implement MedLeak on medical image and text datasets, and the proposed privacy attack is highly effective on both types of datasets.
Recovered examples from the COVIDx CXR-4 dataset, Kaggle Brain Tumor MRI dataset, and MedAbstract dataset. The original images are on the left and the recovered ones are on the right. The text samples are truncated due to space limitations. Recovery failure samples are marked in red rectangles.
Reference
Shanghao Shi, Ning Wang, Yang Xiao, Chaoyu Zhang, Yi Shi, Y. Thomas Hou, and Wenjing Lou. “Scale-MIA: A Scalable Model Inversion Attack against Secure Federated Learning via Latent Space Reconstruction”. In Network and Distributed System Security Symposium 2025 (NDSS 25). [PDF]
Shanghao Shi, Md Shahedul Haque, Abhijeet Parida, Chaoyu Zhang, Marius Linguraru, Y. Thomas Hou, Syed Anwar, and Wenjing Lou. “MedLeak: Multimodal Medical Data Leakage in Secure Federated Learning with Crafted Models”. In ACM/IEEE International Conference on Connected Health: Applications, Systems and Engineering Technologies (CHASE 25) [PDF]